Jupyter MCP
Jupyter MCP Server enables real-time interaction with Jupyter notebooks, allowing AI models to edit, execute, and document code for data analysis and visualization. Instead of just generating code suggestions, AI can actually run Python code and see the results.
This integration gives Jan the ability to execute analysis, create visualizations, and iterate based on actual results - turning your AI assistant into a capable data science partner.
Available Tools
Section titled “Available Tools”The Jupyter MCP Server provides 12 comprehensive tools:
Core Operations
Section titled “Core Operations”append_execute_code_cell: Add and run code cells at notebook endinsert_execute_code_cell: Insert and run code at specific positionsexecute_cell_simple_timeout: Execute cells with timeout controlexecute_cell_streaming: Long-running cells with progress updatesexecute_cell_with_progress: Execute with timeout and monitoring
Cell Management
Section titled “Cell Management”append_markdown_cell: Add documentation cellsinsert_markdown_cell: Insert markdown at specific positionsdelete_cell: Remove cells from notebookoverwrite_cell_source: Update existing cell content
Information & Reading
Section titled “Information & Reading”get_notebook_info: Retrieve notebook metadataread_cell: Examine specific cell contentread_all_cells: Get complete notebook state
Prerequisites
Section titled “Prerequisites”- Jan with MCP enabled
- Python 3.8+ with uv package manager
- Docker installed
- OpenAI API key for GPT-5 access
- Basic understanding of Jupyter notebooks
Enable MCP
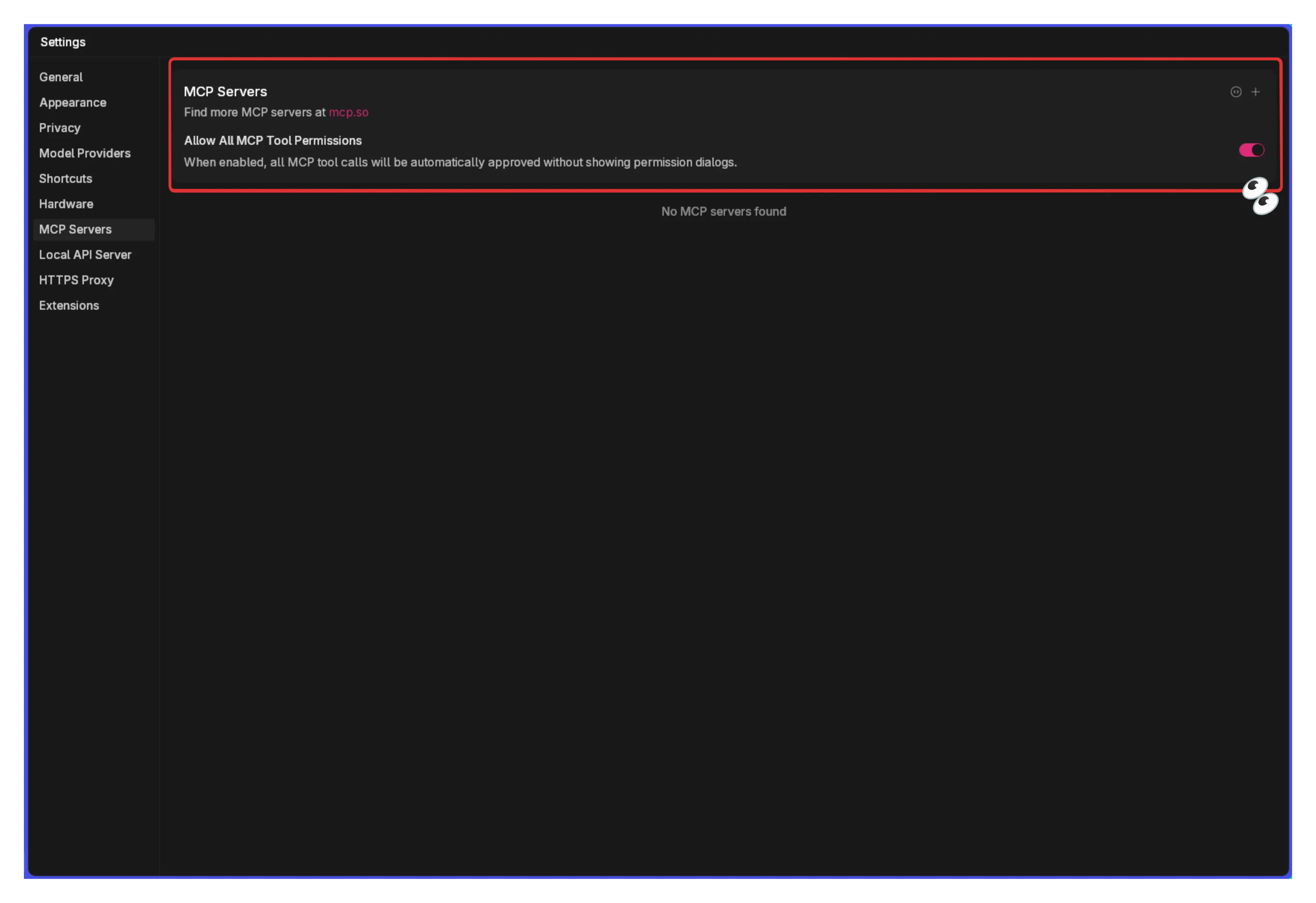
Section titled “Enable MCP”- Go to Settings > MCP Servers
- Toggle Allow All MCP Tool Permission ON
Install uv Package Manager
Section titled “Install uv Package Manager”If you don’t have uv installed:
# macOS and Linuxcurl -LsSf https://astral.sh/uv/install.sh | sh
# Windowspowershell -c "irm https://astral.sh/uv/install.ps1 | iex"Create Python Environment
Section titled “Create Python Environment”Set up an isolated environment for Jupyter:
# Create environment with Python 3.13uv venv .venv --python 3.13
# Activate environmentsource .venv/bin/activate # Linux/macOS# or.venv\Scripts\activate # Windows
# Install Jupyter dependenciesuv pip install jupyterlab==4.4.1 jupyter-collaboration==4.0.2 ipykerneluv pip uninstall pycrdt datalayer_pycrdtuv pip install datalayer_pycrdt==0.12.17
# Add data science librariesuv pip install pandas numpy matplotlib altairStart JupyterLab Server
Section titled “Start JupyterLab Server”Launch JupyterLab with authentication:
jupyter lab --port 8888 --IdentityProvider.token heyheyyou --ip 0.0.0.0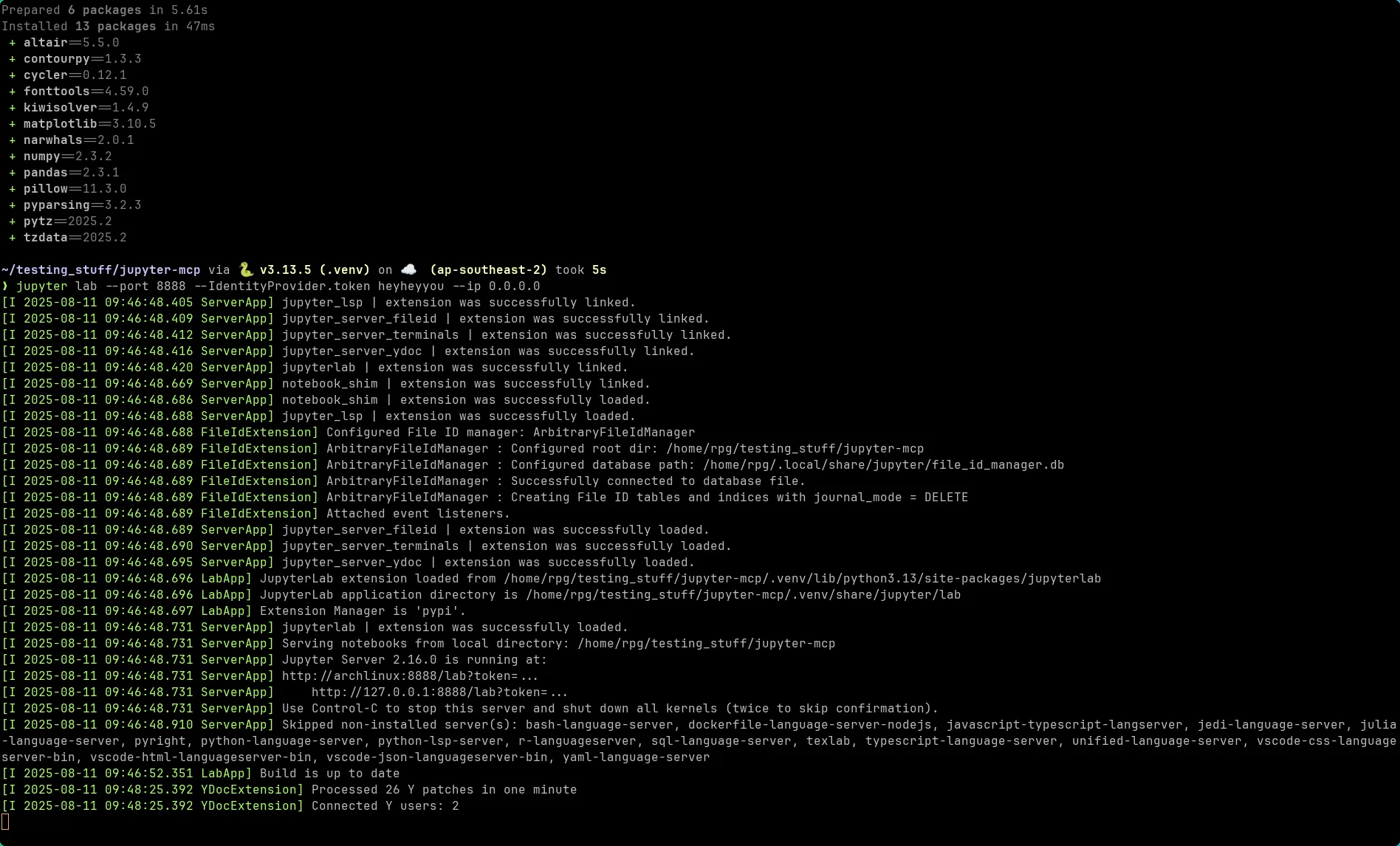
The server opens in your browser:
Create Target Notebook
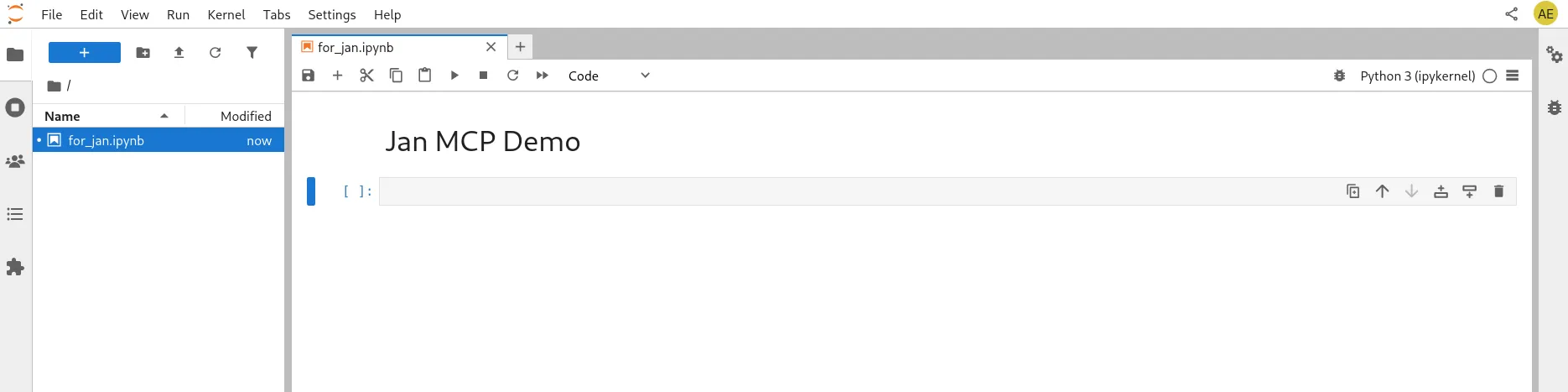
Section titled “Create Target Notebook”Create a new notebook named for_jan.ipynb:
Configure MCP Server in Jan
Section titled “Configure MCP Server in Jan”Click + in MCP Servers section:
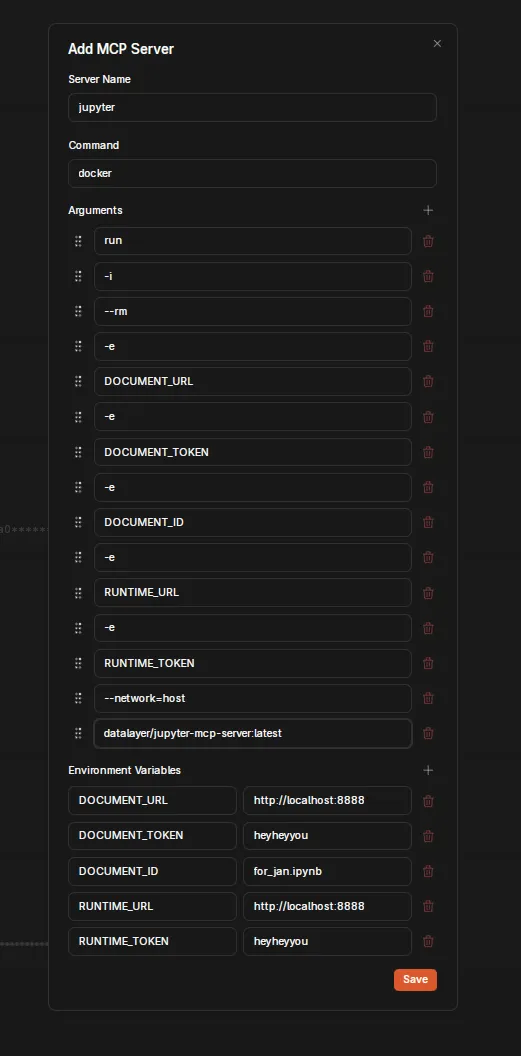
Configuration for macOS/Windows:
- Server Name:
jupyter - Command:
docker - Arguments:
run -i --rm -e DOCUMENT_URL -e DOCUMENT_TOKEN -e DOCUMENT_ID -e RUNTIME_URL -e RUNTIME_TOKEN datalayer/jupyter-mcp-server:latest
- Environment Variables:
- Key:
DOCUMENT_URL, Value:http://host.docker.internal:8888 - Key:
DOCUMENT_TOKEN, Value:heyheyyou - Key:
DOCUMENT_ID, Value:for_jan.ipynb - Key:
RUNTIME_URL, Value:http://host.docker.internal:8888 - Key:
RUNTIME_TOKEN, Value:heyheyyou
- Key:
Using OpenAI’s GPT-5
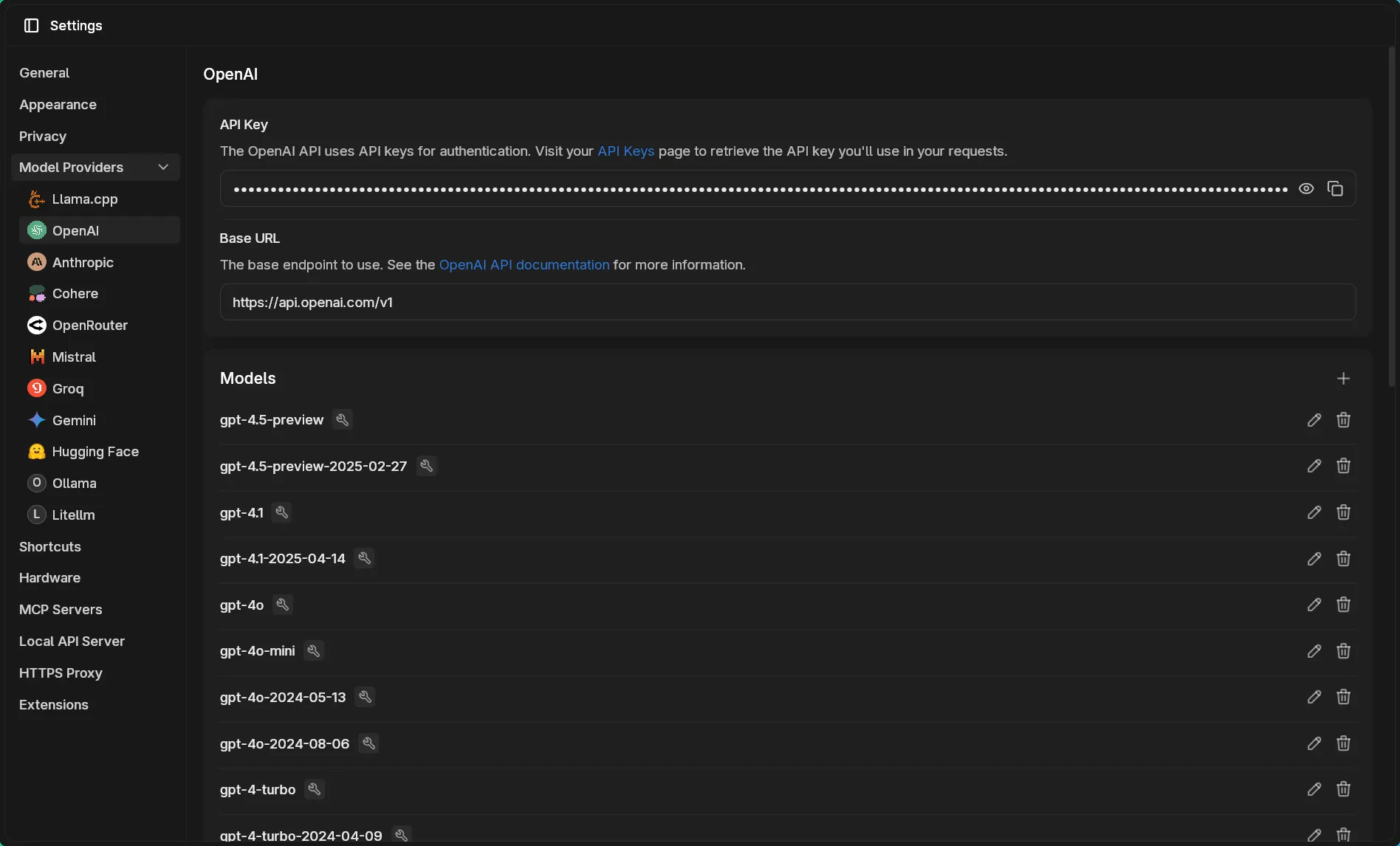
Section titled “Using OpenAI’s GPT-5”Configure OpenAI Provider
Section titled “Configure OpenAI Provider”Navigate to Settings > Model Providers > OpenAI:
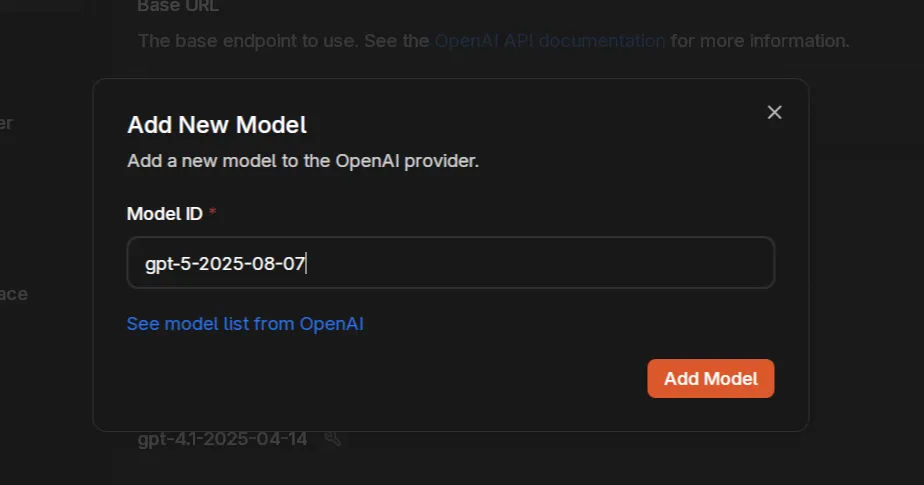
Add GPT-5 Model
Section titled “Add GPT-5 Model”Since GPT-5 is new, you’ll need to manually add it to Jan:
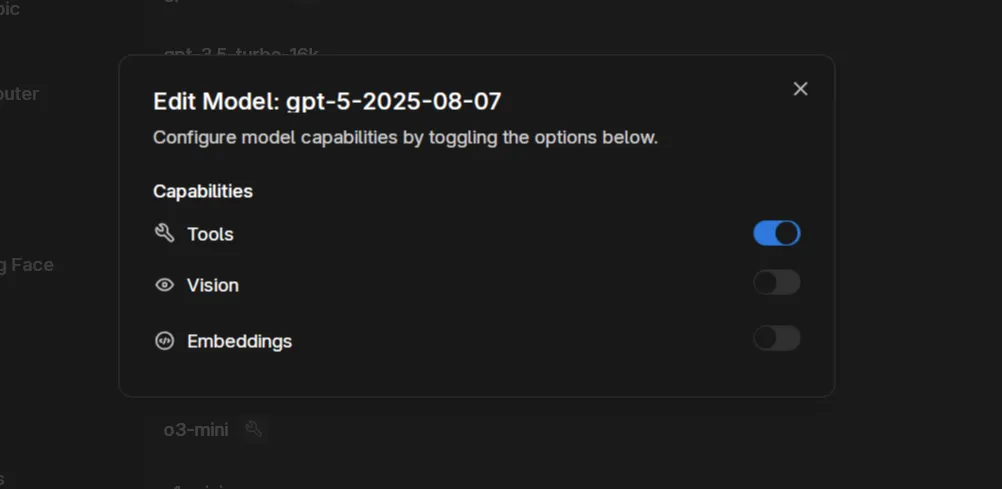
Enable Tool Calling
Section titled “Enable Tool Calling”Ensure tools are enabled for GPT-5:
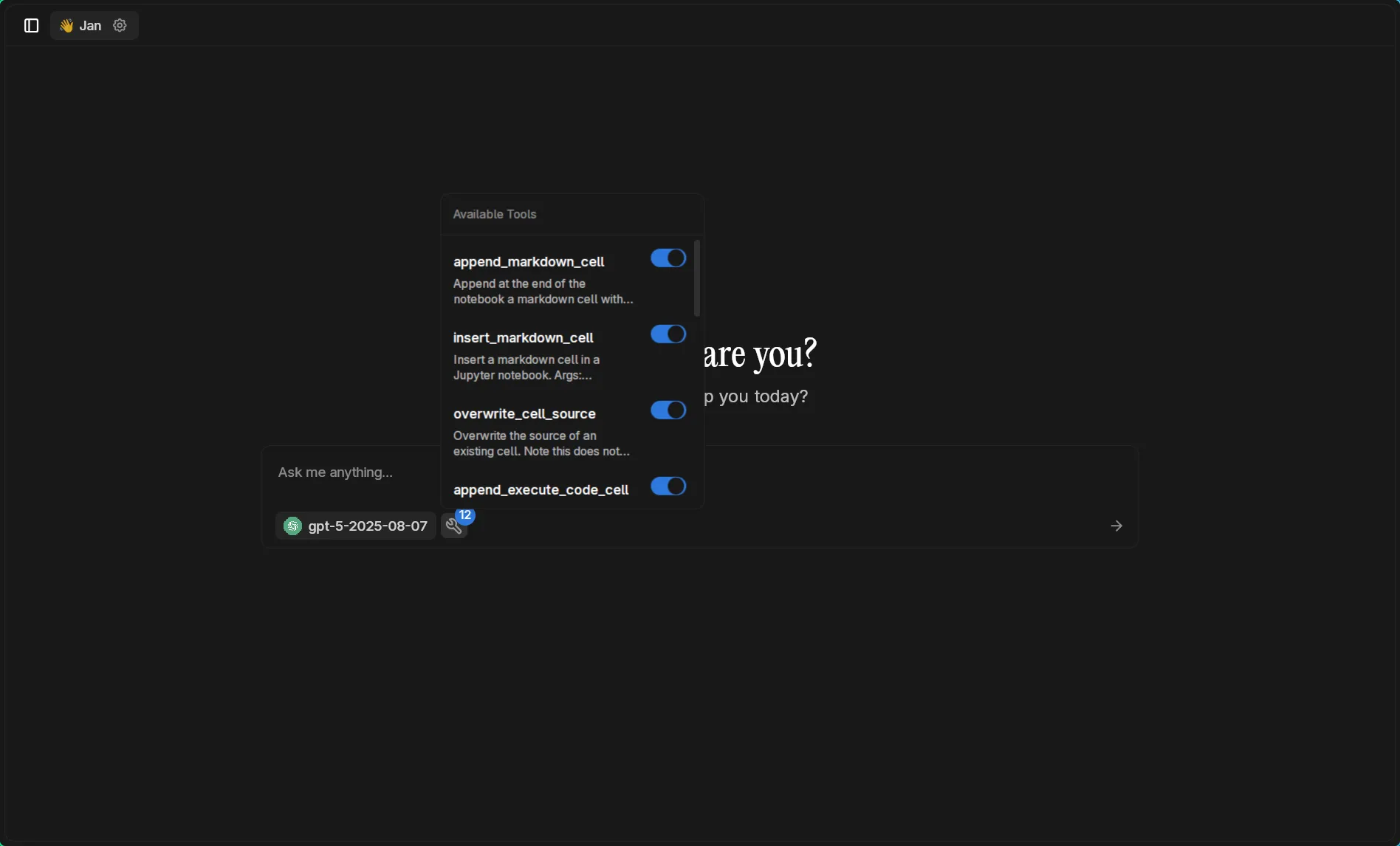
Verify Tool Availability
Section titled “Verify Tool Availability”Start a new chat with GPT-5. The tools bubble shows all available Jupyter operations:
Initial Test
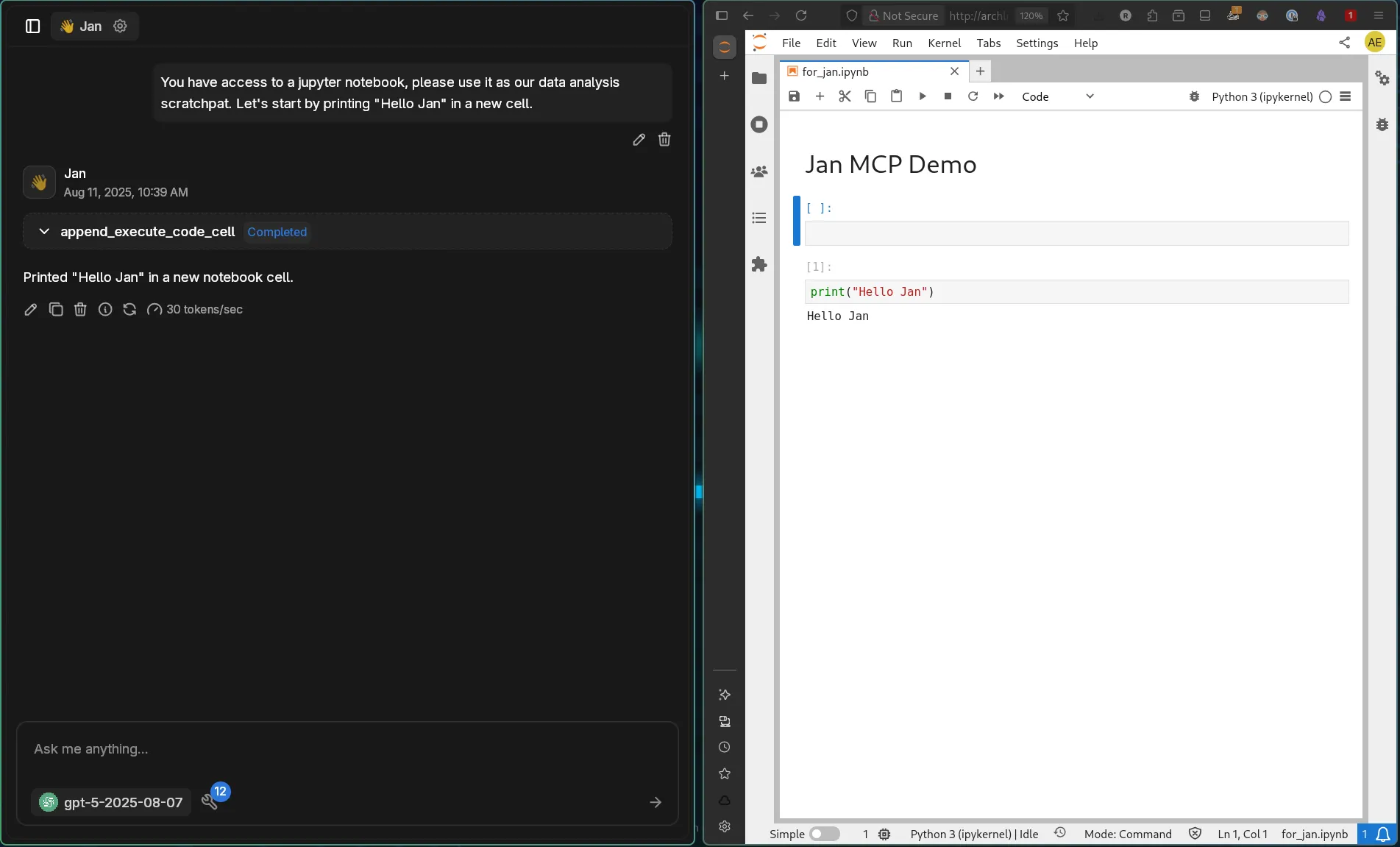
Section titled “Initial Test”Start with establishing the notebook as your workspace:
You have access to a jupyter notebook, please use it as our data analysis scratchpad. Let's start by printing "Hello Jan" in a new cell.GPT-5 creates and executes the code successfully:
Advanced Data Analysis
Section titled “Advanced Data Analysis”Try a more complex task combining multiple operations:
Generate synthetic data with numpy, move it to a pandas dataframe and create a pivot table, and then make a cool animated plot using matplotlib. Your use case will be sales analysis in the luxury fashion industry.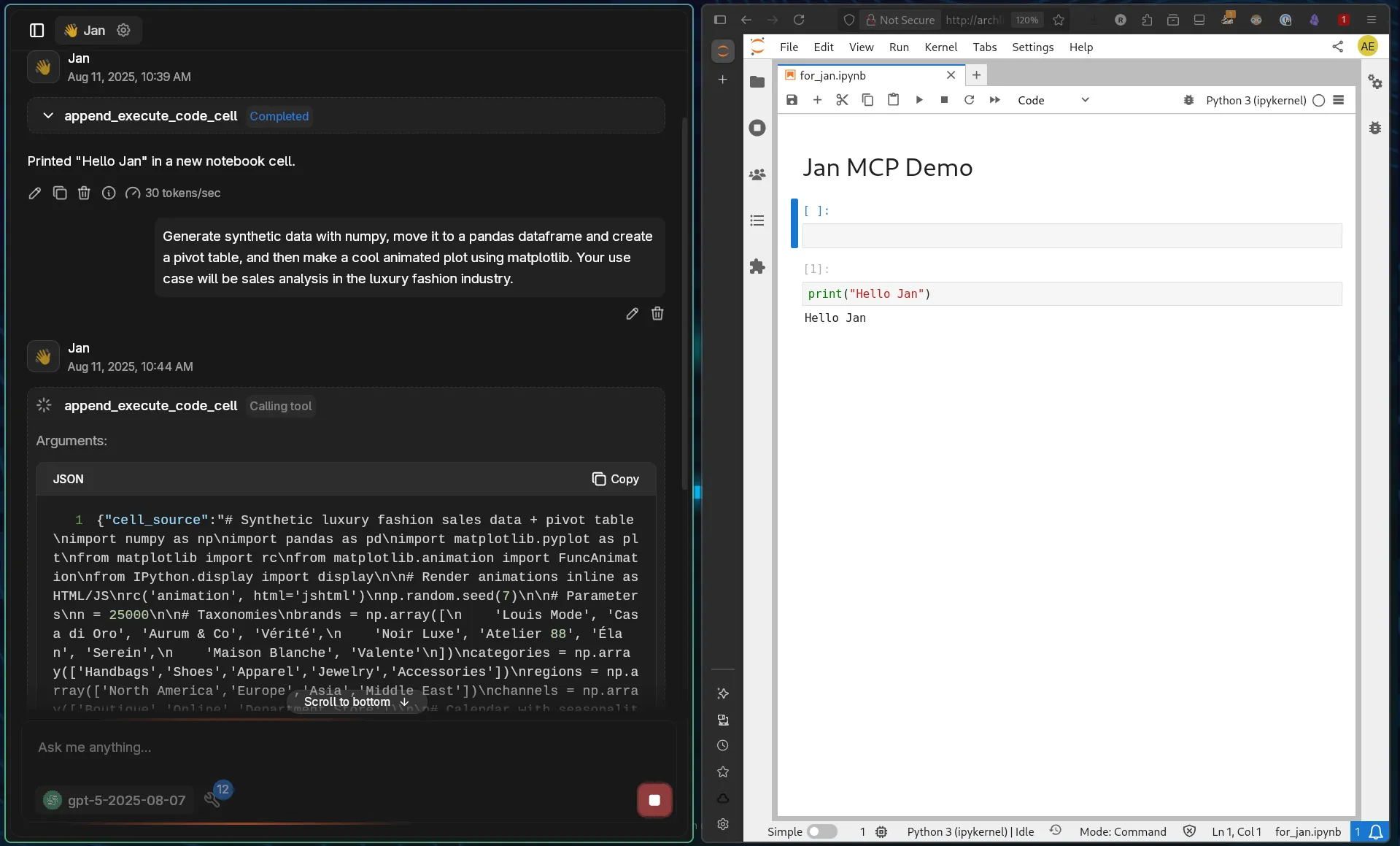
Watch the complete output unfold:
Example Prompts to Try
Section titled “Example Prompts to Try”Financial Analysis
Section titled “Financial Analysis”Create a Monte Carlo simulation for portfolio risk analysis. Generate 10,000 scenarios, calculate VaR at 95% confidence, and visualize the distribution.Time Series Forecasting
Section titled “Time Series Forecasting”Generate synthetic time series data representing daily website traffic over 2 years with weekly seasonality and trend. Build an ARIMA model and forecast the next 30 days.Machine Learning Pipeline
Section titled “Machine Learning Pipeline”Build a complete classification pipeline: generate a dataset with 3 classes and 5 features, split the data, try multiple algorithms (RF, SVM, XGBoost), and create a comparison chart of their performance.Interactive Dashboards
Section titled “Interactive Dashboards”Create an interactive visualization using matplotlib widgets showing how changing interest rates affects loan payments over different time periods.Statistical Testing
Section titled “Statistical Testing”Generate two datasets representing A/B test results for an e-commerce site. Perform appropriate statistical tests and create visualizations to determine if the difference is significant.Performance Considerations
Section titled “Performance Considerations”Context Management
Section titled “Context Management”- Each tool call adds to conversation history
- 12 available tools means substantial system prompt overhead
- Local models may need reduced tool sets for reasonable performance
- Consider disabling unused tools to conserve context
Cloud vs Local Trade-offs
Section titled “Cloud vs Local Trade-offs”- Cloud models (GPT-5): Handle multiple tools efficiently with large context windows
- Local models: May require optimization, reduced tool sets, or smaller context sizes
- Hybrid approach: Use cloud for complex multi-tool workflows, local for simple tasks
Security Considerations
Section titled “Security Considerations”Authentication Tokens
Section titled “Authentication Tokens”- Always use strong tokens - avoid simple passwords
- Never commit tokens to version control
- Rotate tokens regularly for production use
- Use different tokens for different environments
Network Security
Section titled “Network Security”- JupyterLab is network-accessible with
--ip 0.0.0.0 - Consider using
--ip 127.0.0.1for local-only access - Implement firewall rules to restrict access
- Use HTTPS in production environments
Code Execution Risks
Section titled “Code Execution Risks”- AI has full Python execution capabilities
- Review generated code before execution
- Use isolated environments for sensitive work
- Monitor resource usage and set limits
Data Privacy
Section titled “Data Privacy”- Notebook content is processed by AI models
- When using cloud models like GPT-5, data leaves your system
- Keep sensitive data in secure environments
- Consider model provider’s data policies
Best Practices
Section titled “Best Practices”Environment Management
Section titled “Environment Management”- Use virtual environments for isolation
- Document required dependencies
- Version control your notebooks
- Regular environment cleanup
Performance Optimization
Section titled “Performance Optimization”- Start with simple operations
- Monitor memory usage during execution
- Close unused notebooks
- Restart kernels when needed
Effective Prompting
Section titled “Effective Prompting”- Be specific about desired outputs
- Break complex tasks into steps
- Ask for explanations with code
- Request error handling in critical operations
Troubleshooting
Section titled “Troubleshooting”Connection Problems:
- Verify JupyterLab is running
- Check token matches configuration
- Confirm Docker can reach host
- Test with curl to verify connectivity
Execution Failures:
- Check Python package availability
- Verify kernel is running
- Look for syntax errors in generated code
- Restart kernel if stuck
Tool Calling Errors:
- Ensure model supports tool calling
- Verify all 12 tools appear in chat
- Check MCP server is active
- Review Docker logs for errors
API Rate Limits:
- Monitor OpenAI usage dashboard
- Implement retry logic for transient errors
- Consider fallback to local models
- Cache results when possible
Conclusion
Section titled “Conclusion”The Jupyter MCP integration combined with GPT-5’s advanced capabilities creates an exceptionally powerful data science environment. With GPT-5’s built-in reasoning and expert-level intelligence, complex analyses that once required extensive manual coding can now be accomplished through natural conversation.
Whether you’re exploring data, building models, or creating visualizations, this integration provides the computational power of Jupyter with the intelligence of GPT-5 - all within Jan’s privacy-conscious interface.
Remember: with great computational power comes the responsibility to use it securely. Always validate generated code, use strong authentication, and be mindful of data privacy when using cloud-based models.